What is Scalability
A Dataverse database supports large data sets and complex data models. Tables can hold millions of items, and you can extend the storage in each instance of a Microsoft Dataverse database to 4 terabytes. The amount of data available in your instance of Microsoft Dataverse is based on the number and type of licenses that are associated with it. Data storage is pooled between all licensed users, so you can allocate storage as needed for each solution that you build. Incremental storage can be purchased if you need more storage than what is offered within standard licensing.
Microsoft Dataverse structure and benefits
The structure of a Microsoft Dataverse database is based upon the definitions and schema in the Common Data Model. Using the Common Data Model as the basis of a Microsoft Dataverse database simplifies the integration of solutions that use a Common Data Model schema. This is because the Common Data Model is the basis of a Microsoft Dataverse database and uses a Common Data Model schema. The standard tables of the solution are the same. You can take advantage of a rich ecosystem of solutions that vendors created from using the Common Data Model. Best of all, there’s practically no limit to how far you can extend a Microsoft Dataverse database.
Describe tables, columns, and relationships
A table is a logical structure containing rows and columns that represent a set of data. In the screenshot, you see the standard account table and various elements that can be managed as part of it.
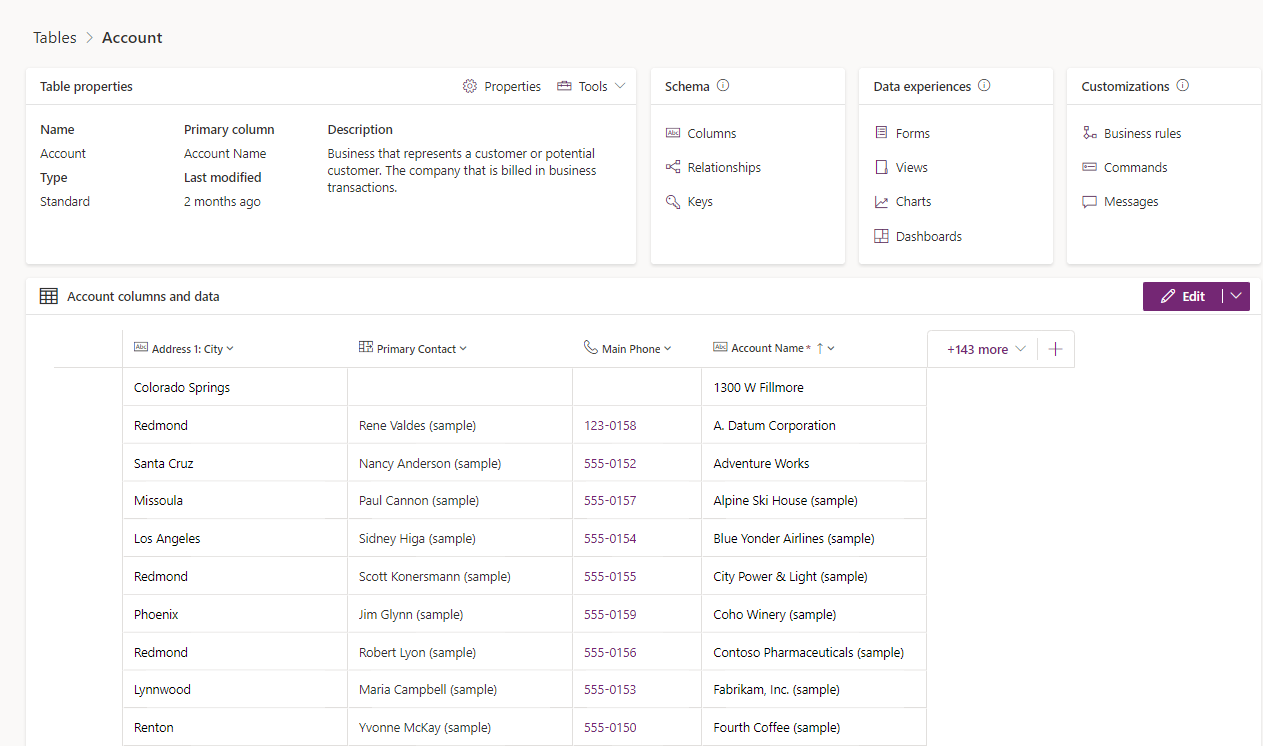
Types of tables
The three types of tables are:
- Standard – Several standard tables, also known as out-of-box tables, are included with a Dataverse environment. Account, business unit, contact, task, and user tables are examples of standard tables in Dataverse. Most of the standard tables included with Dataverse can be customized.
- Managed – Tables that aren’t customizable and are imported into the environment as part of a managed solution.
- Custom – Custom tables are unmanaged tables that are either imported from an unmanaged solution or are new tables created directly in the Dataverse environment.
Columns
Columns store a discrete piece of information within a row in a table. You might think of them as a column in Excel. Columns have data types, meaning that you can store data of a certain type in a column that matches that data type. For example, if you have a solution that requires dates, such as capturing the date of an event or when something occurred, then you store the date in a column with the type Date. Similarly, if you want to store a number, then you store the number in a column with the type of Number.
The number of columns within a table varies from a few columns to a hundred or more. Every database in Microsoft Dataverse starts with a standard set of tables, and each standard table has a standard set of columns.
Understand relationships
To make an efficient and scalable solution for most of the solutions that you build, you need to split up data into different containers (tables). Trying to store everything in a single container would likely be inefficient and difficult to understand.
The following example helps illustrate this concept.
Imagine that you need to create a system to manage sales orders. You need a product list along with the inventory on hand, the cost of the item, and the selling price. You also need a master list of customers with their addresses and credit ratings. Finally, you need to manage sales invoices as well to store invoice data. The invoice should include information such as:
- date
- invoice number
- salesperson
- customer information including address and credit rating
- a line item for each item on the invoice
Each line item should include a reference to the product that you sold. The line item should also provide the proper cost and price for each product. And finally, the line should also decrease the quantity on hand based upon the quantity that you sold in that line item. Creating a single table to support the functionality in the above example would be inefficient. A better way to approach this business scenario is to create the following four tables:
- Customers
- Products
- Invoices
- Line items
Creating a table for each of these items and relating them to one another allows you to build an efficient solution that can scale, while maintaining high performance. Splitting the data into multiple tables also means that you don’t have to store repetitive data or support huge rows with large amounts of blank data. Reporting is also much easier if you split the data into separate tables.
Tables that relate to one another have a relational connection. Relationships between tables exist in many forms, but the two most common are one-to-many and many-to-many, both of which Microsoft Dataverse supports. To learn more about the different relationship types, see: Table relationships.